sqsdの最近のアップデートについて
以前「作った」と書いたsqsdについて↓ taiyoh.hatenablog.com
最近これのバージョンアップを頻繁に行っている。
Release v0.0.4 · taiyoh/sqsd · GitHub
v0.0.3~v0.0.4の差分
社内のgoの達人方にレビューしてもらい、channel capacityを導入したところコードの見通しがものすごく良くなったので、v0.0.4として一旦リリース。
workerに送るqueueをchannelによってブロックできるようにすることで、余計なmutex等を入れずに安全にqueueをworkerに送れるようになった。
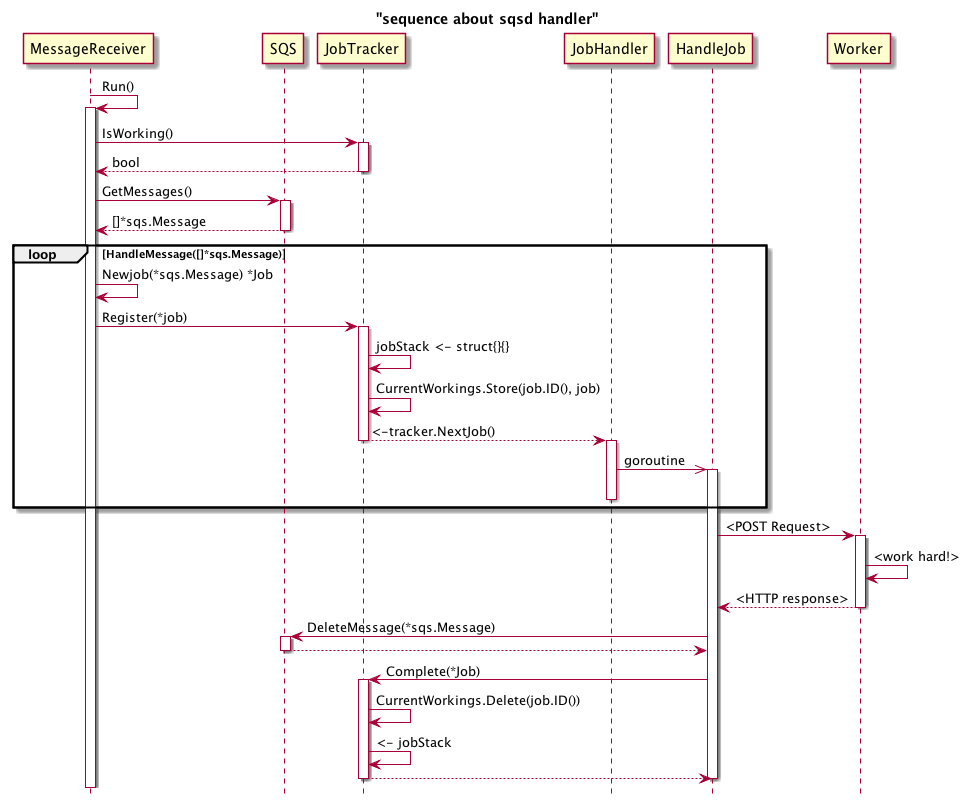
このシーケンス図を同僚に見せたところ、「これは producer-consumerパターン で書くといいですね」というコメントをもらう。
Release v0.0.5 · taiyoh/sqsd · GitHub
producer-consumerパターンは自分の中で咀嚼が必要だったので、一旦保留。
そろそろログ周りを整理したかったので、このQiitaの記事を読んで hashicorp/logutilsを入れることにした
この時点では構造化ログまでは必要ないと思っていて、ログレベルが調整できればいいと考えていた。
Release v0.5.0 · taiyoh/sqsd · GitHub
producer-consumerパターンがやっと自分の中で咀嚼できたのでリファクタリングを開始。やってみたところ、今までJobという名前のstructがqueue自体の保持だけでなくconsumerの責務も負っていることが分かったので、それを分離したところ、それだけでほぼproducer-consumerパターンといえる組み方ができてしまった。あとはそのデザインパターンを適用していることを示すためにJobやWorkerという言葉は避け、producerやconsumerという言葉を使うことにした。
デザインパターンの適用をはっきり見せることができたので、βクオリティということを示したいのでバージョンを思い切って上げることにした。
Release v0.6.1 · taiyoh/sqsd · GitHub
SQSのqueue urlの構築をパラメータから行うようにしてしまったため、例えばローカルで開発する時など、awsに飛ばないようにしなくてはいけない。
そのため、強制的にURLを指定できるようにもした。
また、実際にプロダクトに投入される時のことを想像したとき、万が一workerの起動が遅かった時、queueの取得が先に行われてしまうとvisibility timeoutが発生してしまうのではないか、ということに気づいた。その解決策として、producerの起動前にhealthcheck用のエンドポイントにリクエストを行い、その時のレスポンスコードが200を返したときにworkerの準備ができたとみなすことにした。それが済むまで、SQSへのqueueの取得は行わない。healthcheckに対してはexponential backoffアルゴリズムに従ってリトライを行い、これが規定の秒数に達しても200が返せないときはsqsdごと落とすようにした。この挙動はconfに healthcheck というセクションが定義されている時のみ行われる。optionalとしているが、なるべく定義した方がいいのでは、と考えている。
Release v0.7.0 · taiyoh/sqsd · GitHub
queueの取得の性能について以前からぼんやり気になっていたので調べていたところ、上記URLに答えが書いてあった。(当然金はかかるが)ガンガンリクエストして取りに来てくれ、ということのようなので、遠慮なく一度に複数リクエストを投げられるようにした。v0.0.4の時にchannel capacityの対応を入れていたおかげで、投入部分は何も気にすることなく対応できたのがとてもよかった。
取り急ぎどうしても必要そうな更新は終わったつもりだが、これからまだまだ必要な機能実装はあるかもしれない。直近ではログの構造化を考えている。
また、イケてない箇所は優しくissueをいただけますと :pray: