Ergo42を組み立てています(そしてどうやら失敗しています)
[追記 2018-07-27] 組みあがりました
[/追記]
最近突如として自作キーボードに興味が出てきて、電子工作のスキルなんて全然ないのに道具を揃えてErgo42を組み立ててみることにしました。 (作者のBiacco42さん、ありがとうございます!)
組み立て手順については、qiitaにある組み立てログを参考に作業を進めていました。
ただ、Pro Microの右側の取り付けで盛大にミスをしてしまい、左側と同じ付け方をしてしまいました。 (チップやLEDが見える方を上側にしてしまった) なので慌ててスプリングピンヘッダを切って無理矢理取り外し、Pro MicroもAmazonでほぼ同じものを購入し、正しい向きにした状態で改めて装着しました。
そんなこんなでキースイッチを全部半田付けしていざ試してみたところ、右側のキーボードの左から2番目の縦一列(デフォルトのキーマップで言う「U」「J」「M」「'」)のキーが全て効かない状態になっております。。。 以下、自分なりにトラブルシュートを行ってみました。
- 4つのスイッチを全部差し替えてみましたが、特に挙動に変化はありませんでした
- テスターで導通チェックをしてみましたが、絶縁状態にはなってないようでした
- ダイオードの向きも問題ないようです
- 右側のファームウェア書き込みのついでにいくつかキーを打ってみて、やはり当該のキーだけ打てませんでした
- 左側との連係ミスとは考えづらい
となると、あと考えられるのは
- Pro Microを外した時に必要以上に強い力がかかった
- 目視する限り、基盤には影響はなさそうでした
- ニッパーでスプリングピンヘッダを外す時に一部エッチングが削れてしまったというのはあります
- 半田と半田ごての扱いが未熟でPro Microを痛めた
ですかね。。。 自分のスキルを差し置いて希望だけ書いておくと、Pro Microを使ったキーボードで縦一列が使えなくなる、というのがよくある失敗パターンとしてあって、何かをやり直したら解決する、だといいなぁ。 そうじゃないとしたら、もう1セット買って右側を作り直すしかなさそうですね。。。
 左側は全キー問題なさそうなので、キーキャップまで全部着けました。パステル系のキーキャップを買ったので予想通りかわいい。
左側は全キー問題なさそうなので、キーキャップまで全部着けました。パステル系のキーキャップを買ったので予想通りかわいい。
 この左から二番目の縦一列が全滅です。因みにキースイッチはkailh pro purpleです。打ち心地いいですねこれ。
この左から二番目の縦一列が全滅です。因みにキースイッチはkailh pro purpleです。打ち心地いいですねこれ。
 右側のPro Microを上から見たところです。
右側のPro Microを上から見たところです。
 右側のキーボードを基盤裏から見た図です。
右側のキーボードを基盤裏から見た図です。
Docker for Windows 18.03で/var/run/docker.sockがマウントできなくなってた
sqsdの最近のアップデートについて
以前「作った」と書いたsqsdについて↓ taiyoh.hatenablog.com
最近これのバージョンアップを頻繁に行っている。
Release v0.0.4 · taiyoh/sqsd · GitHub
v0.0.3~v0.0.4の差分
社内のgoの達人方にレビューしてもらい、channel capacityを導入したところコードの見通しがものすごく良くなったので、v0.0.4として一旦リリース。
workerに送るqueueをchannelによってブロックできるようにすることで、余計なmutex等を入れずに安全にqueueをworkerに送れるようになった。
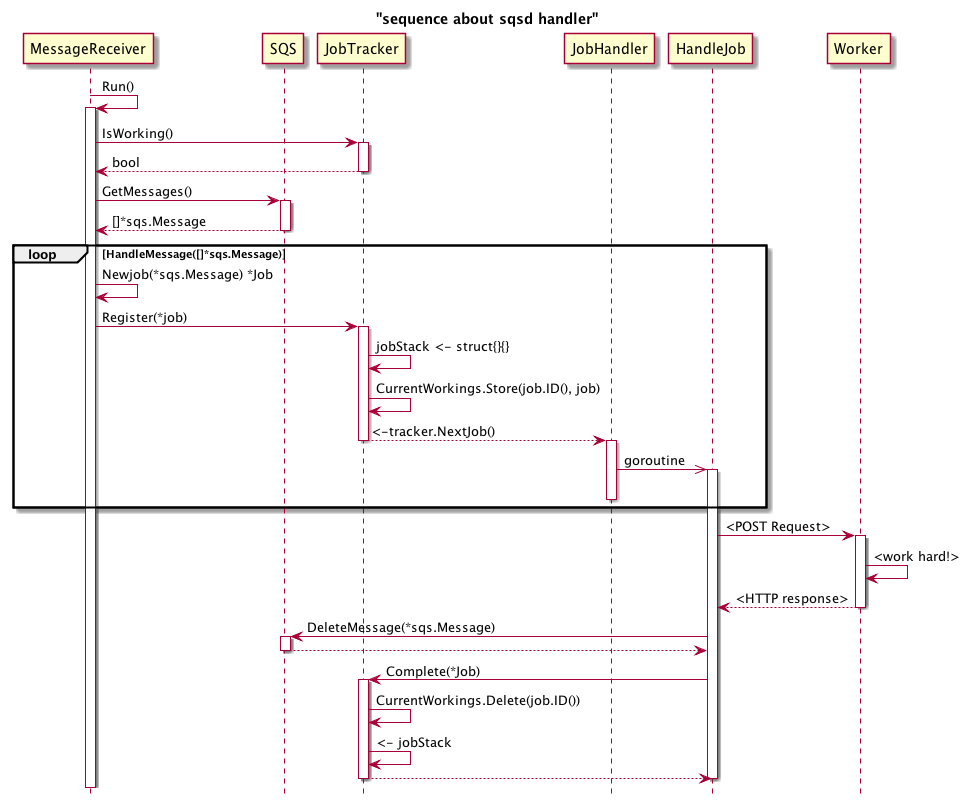
このシーケンス図を同僚に見せたところ、「これは producer-consumerパターン で書くといいですね」というコメントをもらう。
Release v0.0.5 · taiyoh/sqsd · GitHub
producer-consumerパターンは自分の中で咀嚼が必要だったので、一旦保留。
そろそろログ周りを整理したかったので、このQiitaの記事を読んで hashicorp/logutilsを入れることにした
この時点では構造化ログまでは必要ないと思っていて、ログレベルが調整できればいいと考えていた。
Release v0.5.0 · taiyoh/sqsd · GitHub
producer-consumerパターンがやっと自分の中で咀嚼できたのでリファクタリングを開始。やってみたところ、今までJobという名前のstructがqueue自体の保持だけでなくconsumerの責務も負っていることが分かったので、それを分離したところ、それだけでほぼproducer-consumerパターンといえる組み方ができてしまった。あとはそのデザインパターンを適用していることを示すためにJobやWorkerという言葉は避け、producerやconsumerという言葉を使うことにした。
デザインパターンの適用をはっきり見せることができたので、βクオリティということを示したいのでバージョンを思い切って上げることにした。
Release v0.6.1 · taiyoh/sqsd · GitHub
SQSのqueue urlの構築をパラメータから行うようにしてしまったため、例えばローカルで開発する時など、awsに飛ばないようにしなくてはいけない。
そのため、強制的にURLを指定できるようにもした。
また、実際にプロダクトに投入される時のことを想像したとき、万が一workerの起動が遅かった時、queueの取得が先に行われてしまうとvisibility timeoutが発生してしまうのではないか、ということに気づいた。その解決策として、producerの起動前にhealthcheck用のエンドポイントにリクエストを行い、その時のレスポンスコードが200を返したときにworkerの準備ができたとみなすことにした。それが済むまで、SQSへのqueueの取得は行わない。healthcheckに対してはexponential backoffアルゴリズムに従ってリトライを行い、これが規定の秒数に達しても200が返せないときはsqsdごと落とすようにした。この挙動はconfに healthcheck というセクションが定義されている時のみ行われる。optionalとしているが、なるべく定義した方がいいのでは、と考えている。
Release v0.7.0 · taiyoh/sqsd · GitHub
queueの取得の性能について以前からぼんやり気になっていたので調べていたところ、上記URLに答えが書いてあった。(当然金はかかるが)ガンガンリクエストして取りに来てくれ、ということのようなので、遠慮なく一度に複数リクエストを投げられるようにした。v0.0.4の時にchannel capacityの対応を入れていたおかげで、投入部分は何も気にすることなく対応できたのがとてもよかった。
取り急ぎどうしても必要そうな更新は終わったつもりだが、これからまだまだ必要な機能実装はあるかもしれない。直近ではログの構造化を考えている。
また、イケてない箇所は優しくissueをいただけますと :pray:
「エンジニアリング組織論への招待」を読んだ

エンジニアリング組織論への招待 ~不確実性に向き合う思考と組織のリファクタリング
- 作者: 広木大地
- 出版社/メーカー: 技術評論社
- 発売日: 2018/02/22
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (1件) を見る
1章の「get wild and tough」でいきなり引き込まれ、2章で自分がメンタリングされている気分になっていた。読んでるだけで気分がよくなってきたので、自分が今まず欲しているのはこれなのかもしれない。これらを序盤に持ってくるあたり、「まずは自分のスタンスを変え、個々人間の情報の非対称性をなくしていくことが重要だ」と言われているように感じていた。3~4章ではチームビルディングやアジャイル・そしてそこから派生したプロジェクトのイテレーション手法について触れているが、どれもやはり「個人の情報の非対称性が少ない」というのが前提に立った話のように僕は捉えた。裏を返すと、情報の非対称性に対処するという基本的な部分の努力が払われないままリーンやアジャイル、スクラムといった手法を取り入れても、ただ恰好だけ真似しただけで早晩破綻するだろう、とも受け取れる。事実、自分たちのチームのスクラムの体制は半分くらい崩壊しかかっている。導入した当時は「今必要だからスクラムを導入するしかない」と思っていたつもりだったが、今振り返ると、その前にやることがあっただろうと思える。
結構注意しなくては、と思ったのは、4章後半~5章にかけて「適切に権限移譲せよ」と書いてあったのだが、これを微妙な形で適用して結局「プリンシパル・エージェント関係」に陥らないかというのが心配になった。それを抑制するために、まずは個々人間で情報の非対称性を減らし、メンバーが増えてきたらチーム間の合意のためのプロトコルを作って、という形を適用していくのがいいのではと思うが、恥ずかしながら自分にはそうした世界を実感したことはない。
とりあえずこの本は目から鱗が落ちまくってるので、読み終わる前からすでに事業部の何人かにパワープッシュしている。「不確実性を減らす」というエンジニアリングの本質ができる環境を作りたい。
「GraphQL over WebSocket Protocol」という仕組みが提案されてるらしい
というのをたまたま調べものをしてる時に見つけた。 github.com
(以下このプロトコルは GoWP と書きます)
GoWPだとどのクエリでもWebSocket通信上でできるように、ということが想定されているが、何より主眼に置かれてるのはsubscriptionへの対応ではないだろうか。
コネクション確立からクエリの登録までのプロトコルが明文化されているので、そうした足回りは対応ライブラリがあれば任せられそうというのがいいな、と。
例えば、golangでのGoWP対応ライブラリは以下のようなのがある。
これを見つけてから、
subscriptionでストリーミングしたいデータはHTTP通信で外から登録チャンネル毎に受け渡せる- 部外者に見せたくないデータが誤って流れるのを防ぐために、ユーザを指定できるようにしてもいいかも
- アプリケーション上でのIDはJWTで受け渡してAuthenticateのタイミングでライブラリ上でコネクションIDとマッピング
なんてことができるプロキシサーバがあるといいかも。。。と妄想が一気に膨らんだところだった。
ただ、恐らくまだGraphiQLが対応してないので、今までと同じような開発体制が組めないというのはデメリットとしてありそう。
あと、ユーザ指定して任意のメッセージをサーバから送りたい、というための仕組みとしては kuiperbeltが既にあるので、そもそもserver pushの土管が用意できればいいだけなのにそこまでGraphQL使わないといけないのかとか、色々考えることはある。
GraphQLのMutationのビジネスロジックのエラーはどうハンドリングすればいいのか
最近調査していた内容のメモ。
GraphQLのJSONレスポンスは data と errors の2つのキーに内容が大別される。
基本的に、期待するレスポンスが返せないときは errors にエラー内容が入るというのがGraphQLでやろうとしていることだが、特にMutationにおけるビジネスロジックのエラーはどう記述すればいいだろうか。
恐らくFacebook的には「ダメです!」とエラーダイアログを表示させて終了なのかもしれないが、世の中のサービスが全部それに倣っているということはなく、エラーとなった要素をクライアント側で特定して赤くしたりエラー文言を添えたりしたい、なんてケースはよくある。自分の担当しているサービスもそんな感じだ。
ひとまずRelayのドキュメントを開いてみる→ Mutations · Relay
ざっくりと「レスポンスには(追加・削除含め)変更のあったTypeのオブジェクトを返せ」という風に僕は読んでいる。エラーについては特に記述はなく、 GraphQLのレスポンスとしての errors に全て委ねているようだ。
RelayだけがGraphQLのプロトコルではないので(強力ではあるが)、他にないかと自分が軽く調べてみた限り、大きく2つの方法があるらしい。
1. errors のデータ構造を拡張する
にその一例がある。確かに、という気持ちはあるが、今自分の使っているPerl版GraphQLライブラリはパラメータがかなり厳密に定められているので、そこに手を入れるとなるとモンキーパッチが必須になる。本家にpr送っても通るイメージが湧かない。パス。
だと、ライブラリのエラーオブジェクト自体を差し替えるというアイディアもある。が、これもPerl版GraphQLライブラリだと errors に入れられるのは GraphQL::Error オブジェクトが要素となる配列しか認められてないので、上記と同様のコメントになる。
2. data 側のレスポンスの型としてビジネスロジックでのエラーを返せるようにする
結論が出ないままcloseされていて悲しみしか感じない。が、このissueを参照する形で
Rust版GraphQLライブラリでのやりとりを見つけた。 data.<mutation>.errors なら自分で専用の型を作ればいいだけなので、僕が見てきた方法の中ではこれが一番穏当で現実的なプランに見える。
もうちょっと調べてみたら、Ruby版GraphQLライブラリのドキュメントでも同様の内容があった→GraphQL - Mutations
が、これだと独自のレスポンス形式になるので、この取り決めがサービス内全体で適用できればいいが、Relayからはかなり逸脱しているようにも見える。その点の注意は必要そうだ。
まとめ
現時点だと、自分の担当サービスもビジネスロジックのエラーは data.<mutation>.errors を入れる方向で進めようとしている。Relayを踏襲するかどうかは実は検討中。
Perl版GraphQLライブラリにおけるresolverの定義方法(修正版)
これについて、自分がライブラリの実装方法について大きな誤解をしていたのでここに訂正させていただきます。
開発環境にGraphiQLを導入しようとしてinspectがうまくいかず、
原因の調査していたところ、どうやらresolverの定義方法が想定と違っていたのがわかりました。
Perl版GraphQLライブラリの場合、GraphQL::Execution::executeの引数に一次請けとしてのresolverを入れておく必要があり、この中でどのfieldなのかをまず解決する必要がありました。
ということで、以前提示したサンプルは以下のように修正されます。
gistc9aa7a6db938d4f0ad9abae4e25836a5
この組み方でGraphiQLが正常に動作することは確認しています。resolverを特定するために $info の値を解析する必要があるというところでまだ改善の余地はありそうですが、変な注入の方法よりはずっとよさそう。